#howto - Guida all'utilizzo di git
Quando si parla di software di versioning, git è sicuramente il primo programma che ci viene in mente. È l’alternativa più popolare a sistemi come svn, utilizzata anche in ambito enterprise.
Per chi non lo sapesse, un software di versioning consente di conservare “la storia” delle modifiche di una determinata cartella con tutti i suoi file e le sue sottocartelle oppure, più comunemente, di un progetto. Questo approccio, particolarmente adottato nei progetti di programmazione, consente di tenere traccia degli autori delle modifiche, modificare su più fronti i contenuti di quelle cartelle senza intralciarsi l’un l’altro o, eventualmente, di annullare delle modifiche specifiche.
Git è esattamente tutto questo. Ma, soprattutto, è stato creato da Linus Torvalds. Sì, proprio lui, quello di Linux. FUCK YOU NVIDIA!
Piccole precisazioni
Sono necessarie alcune precisazioni:
- l’articolo non coprirà l’intero sapere umano su git. Lo scopo, infatti, è quello di introdurre le meccaniche alla base, permettendo, a chi ci si addentra, di avere sempre qualche riferimento da cui iniziare o a cui tornare per dubbi strutturali;
- prima di applicare qualsiasi nozione presente in questo articolo su progetti di grandi dimensioni e/o con dati importanti, ricordatevi di effettuare dei test su delle copie e di eseguire dei backup. Tenete presente, infatti, che
gitè uno strumento potente e che, pur potendoci aiutare molto, allo stesso tempo, può farci perdere ore di lavoro, se usato male.Linux/hub declina ogni responsabilità per i danni derivanti da un uso improprio delle informazioni contenute nel sito.
- tutte le immagini dell’articolo sono interpretazioni create dall’autore dell’articolo (strumenti utilizzati: Suite Libreoffice, G.I.M.P.).
Legenda
I contenuti tra parentesi quadrate ([]) all’interno dei comandi sono da intendersi come da sostituirsi con i valori di proprio interesse.
Ad esempio, di fronte al contenuto comando [il tuo nome], se il proprio nome è Mario, il risultato atteso sarà comando Mario (le parentesi quadre, ovviamente, non sono da includersi nella sostituzione finale).
Installazione
Git è un software multipiattaforma, perciò è disponibile su ogni piattaforma tramite lo store o il package manager del sistema, oppure ancora attraverso il sito web ufficiale. Sono disponibili anche diverse interfacce grafiche che possono semplificare il suo operato, ma sconsiglio vivamente di usare GUI nel caso in cui non si riuscisse ad utilizzare git da terminale. La strada più facile, infatti, non significa che sia sempre la migliore, soprattutto se non si conosce la struttura ed il funzionamento del software: ricordatevi che in ballo ci potrebbero essere progetti personali oppure, ancora peggio, quelli della propria azienda.
A questo punto installiamo git tramite i package manager delle distribuzioni più utilizzate:
# Debian, Ubuntu e derivate
apt install git
# Fedora e derivate
dnf install git
# Arch Linux e derivate
pacman -S git
Per maggiori approfondimenti sull’installazione (altre distro, installazione manuale ecc..) potete consultare questo nostro articolo.
Comprendere git
Git è abbastanza banale da usare, ma è prima necessario comprendere la struttura su cui è basato.
Innanzitutto, Git è un sistema di controllo delle versioni distribuito; la maggior parte dei sistemi di questo tipo non memorizza i file in sé, ma ne ricostruisce la struttura, partendo dalla storia, attraverso una piccola serie di file binari che ne tracciano le modifiche.
Git prevede 3 stati di memorizzazione per i file:
- normalmente questi si trovano nella working area, che consiste nello stato in cui si trovano i file su cui si sta lavorando, su cui si attuano delle modifiche e dove, eventualmente, se ne aggiungono di nuovi;
- terminate le modifiche, si possono, quindi, spostare i file nella staging area; nelle cartelle di
gitvengono aggiunti gli object relativi alle informazioni su quali sono i file modificati; - si procede, infine, allo spostamento dei file nella repository, dove vengono creati i file ‘incremento’ che descrivono come si è evoluta la propria working area;
Da qui in poi, in genere, il codice viene inviato nei repository remoti da noi impostati.
Giusto per essere chiari, possiamo identificare queste 3 aree anche all’interno del nostro file system:
- la working area, che rappresenta i file su cui lavoriamo, ossia tutta la nostra cartella progetto;
- la staging area, che, in realtà, è fittizia, poichè si tratta di una serie di file che indicano quali documenti sono cambiati dall’ultimo commit, infatti i nuovi file di tracking vengono già inseriti nel repository di interesse;
- infine, il repository, che è interamente localizzato nella cartella nascosta dentro il nostro progetto
.git.

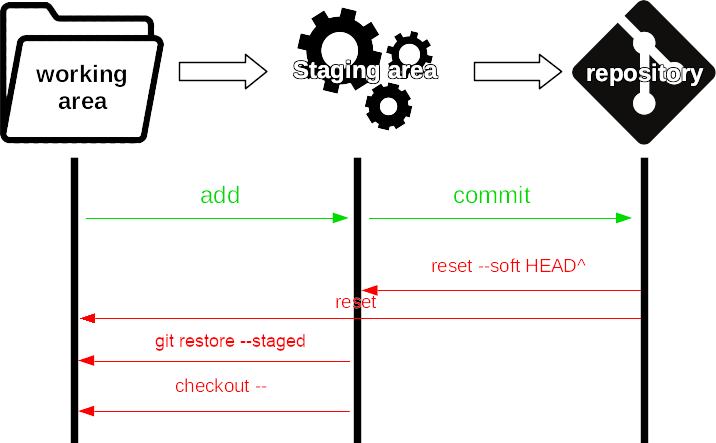
Il primo movimento dalla working area alla staging area è detto “operazione di add”, mentre il secondo movimento da staging a repository è detto “operazione di commit”. Si veda, qua in basso, la differenza tra tre repository prima della add, dopo la add e dopo il commit:

Quando si punta ad un *repository remoto*, gli scambi di codici con quello locale son detti operazione di **pull** e operazione di **push**. “Remoto” in realtà è una parola un po’ fuorviante, questo perchè l’URL può essere anche locale. Il senso di un’operazione del genere non è banale né solo didattica: ad esempio possiamo puntare una cartella del nostro file system che è poi sincronizzata con una cloud dati. Io utilizzo questo sistema per sincronizzare i miei progetti con Dropbox e Mega, ad esempio.
I repository puntati hanno poi dei “nomi” (in genere origin), funzionalità che crea la possibilità di gestirne anche più di uno decidendo volta per volta dove effettuare pull e push. Si tratta di una tecnica utile quando si ha a che fare con progetti di lavoro dove non si hanno i permessi di creare branch nuovi.
Creare una repository
Iniziamo, quindi, dalle basi, creando una repository git nella nostra cartella di progetto. Supponiamo che ci siano queste tre cartelle:
- cartellaproj, che contiene i file di progetto in cui scriviamo i codici;
- reporemoto1, che contiene la sola repository, potrebbe essere locale o remota, ma non sarà direttamente “scrivibile”
- repo2, che contiene sia i file di progetto in cui si può scrivere, sia la repo, come una sorta di copia-clone di cartellaproj, da considerare come se fosse una directory su un altro PC, che sia quello su cui lavoriamo o quello di un nostro collega.
Nella cartellaproj potrebbero già esserci file, ma ciò non è importante. Si entri, quindi, nella cartella e si digiti:
git init
A questo punto verrà creata la repository vuota. Se si hanno già dei file possiamo aggiungerli e committarli.
Nel caso in cui si volesse creare una cartella che funzioni solo da repository, senza avere la necessità di scriverci i file ma per utilizzarla per clonare, mandare il codice e condividerlo con altre postazioni, bisogna creare una repository minimale. Spostiamoci nella cartella reporemoto1 ed eseguiamo:
git init --bare
Facendo, ora, un confronto tra quello che viene creato nella cartella reporemoto1 e quello presente in cartellaproj notiamo subito enormi differenze. Supponendo, ad esempio, che che nella cartella di progetto ci fossero già dei file .c, la situazione sarebbe simile a questa:
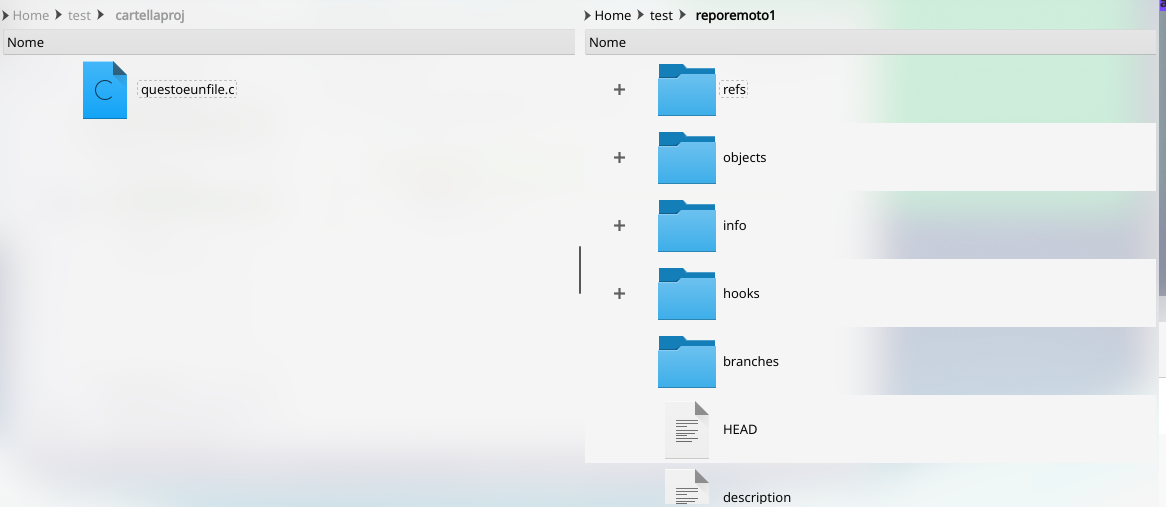
In cartellaproj sembrano siano semplicemente rimasti gli stessi file di prima senza alcuna apparente modifica, ma in realtà esiste ora una cartella nascosta **.git** che fondamentalmente ha la stessa identica struttura della cartella reporemoto1.
Concentriamoci, quindi, su ciò che invece si può notare, ovvero cosa è apparso nella cartella reporemoto1: essenzialmente sono tutti file che costituiscono la struttura di git, definiscono i vari branch, gli stati del progetto, la storia dei file ed i log delle modifiche. Qui viene anche identificata la differenza tra un file che si trova in stato di add e uno che invece è stato mandato al commit.
Si troveranno, però, all’interno degli oggetti binari e non direttamente modificabili, con nomi lunghi e numerici, totalmente diversi da quelli identificativi degli effettivi file del progetto.
Si entri nella cartella repo2 e si inizializzi una repository non minimale vuota (git init) come fatto per cartellaproj.
Aggiungere una repository remota
A scopo dimostrativo, le relazioni tra i vari progetti saranno strutturate così:
- cartellaproj e repo2 punteranno alla repository remota reporemoto1
- cartellaproj avrà una seconda repository remota, cioè repo2/.git
Per realizzare questi passaggi è necessario (dopo essere entrati nella cartella) scrivere un’istruzione, come la seguente, nel proprio terminale:
git remote add [nomerepository] [percorso completo repository]
Supponendo che le cartelle d’esempio, qui trattate, siano nella nostra cartella home, una volta entrati nella cartella cartellaproj possiamo scrivere:
git remote add repository1 ~/reporemoto1/
git remote add repository2 ~/repo2/.git
Si noti subito la differenza: dato che reporemoto è una repository minimale, il percorso indicato per aggiungerlo come repository remota è la cartella stessa. Differente è il caso di repo2, che invece necessita che venga indicato nel path la sua cartella .git. Normalmente comunque si ha a che fare con URL internet, dove questa differenza non ha alcun peso.
Si entri, ora, nella cartella repo2 e si digiti:
git remote add origin ~/reporemoto1
Si noti che i nomi scelti per i repository non sono per niente vincolanti e scelti in totale libertà. Bisognerà, comunque, sempre tenerli a mente perchè indispensabili quando si inizierà a dialogare tra locale e remoto.
File da ignorare
Non tutti i file devono essere registrati nella storia di un progetto. Parlando di programmazione, ad esempio, è inutile che vengano registrati binari compilati (avendo il sorgente possono essere ricompilati), configurazione dell’IDE, cartelle contenti output e log dell’applicazione e quant’altro.
Per questo git dà la possibilità di aggiungere nella cartella di progetto un file speciale, chiamato .gitignore (con il punto davanti, su sistemi UNIX sarà quindi un file nascosto), così strutturato: ogni riga indica un file che **deve essere ignorato** da git.
Qui si può indicare anche un’intera cartella (verranno quindi ignorati tutti i file dentro, ricorsivamente) oppure utilizzare dei caratteri jolly ( come *, per indicare una qualsiasi combinazione di caratteri, oppure ?, per indicare un singolo carattere variabile) per escludere i file con dei nomi specifici.
Si consideri un file gitignore scritto come segue:
bin/
*.class
.classpath
.project?
src/*/esempi/
Ecco alcuni chiarimenti:
bin/: si esclude la cartella bin e tutte le sue sottocartelle (molti IDE mettono all’interno di questa cartella i file compilati);*.class: si escludono tutti i file che finiscono con .class (i file compilati di Java);.classpath: si esclude il file che si chiama .classpath (usato da IDE come Eclipse per indicare il classpath di Java);.project?: si escludono i file che iniziano con .project ma che hanno un altro carattere dopo, ad esempio .projects, oppure le cartelle che si chiamano .project (poichè corrisponde a .project/);src/*/esempi/: esclude la cartella esempi presente in src;
ATTENZIONE: i file .gitignore non sono retroattivi, se si aggiunge un file da ignorare a posteriori e questo è già stato registrato, non sarà eliminato, ma, semplicemente, non verranno più registrate le sue modifiche. Per correggere questo comportamento, bisogna rimuovere il file dalla cache.
Uso base di git
L’uso base di git è già sufficiente a gestire da soli, oppure in piccoli gruppi, un progetto. Le operazioni che si vedranno in questa sezione comprendono l’aggiunta di file ai vari alberi di lavoro, la rimozione e la modifica, ma anche la sincronizzazione di codice con un repository remoto. Prima di tutto, però, vediamo la configurazione dell’utente.
Configurazione utente
Senza aver compreso a dovere questa sezione, sarà molto comune riscontrare errori in alcune fasi, soprattutto durante le operazioni di commit e push. Si proceda, quindi, ad interrogare lo stato delle configurazioni del proprio utente (che a rigor di logica, a git appena installato, dovrebbero essere vuote o mancanti):
- Per il nome si dovrà digitare:
git config --global user.name - Per l’email occorrerà scrivere:
git config --global user.email
Per modificarle basta specificare il nostro nome o la nostra email dopo il valore richiesto. Ad esempio, per modificare il nome, possiamo digitare:
git config --global user.name "Nome Utente"
Le configurazioni global si riferiscono all’utente su qualunque progetto, e risiedono, in genere, nelle cartelle di configurazione del sistema (ad esempio /etc/gitconfig, oppure ~/.gitconfig, nel caso di sistemi Linux) e sono, quindi, condivise, a meno di configurazioni di progetto diverse, che invece vanno impostate dopo essere entrati nella cartella specifica ed aver digitato lo stesso comando, ma senza questa determinata opzione. Per cambiare il nome utente ad un singolo progetto, infatti, è possibile utilizzare il comando in questa maniera:
git config user.name "Nickname per progetto personale"
Questa differenza può essere utile se si vuole distinguere la firma (intesa come email e nome) che si apporterebbe su un progetto di lavoro da quella che, invece, si vuole che risulti su un progetto personale.
Potrebbe essere necessario impostare altri due parametri per ottenere una configurazione che non darà noie, cioè l'editor di testo e un merge tool esterno:
-
Editor di testo: alcune operazioni, come la realizzazione di un messaggio di commit, necessitano la scrittura di testi più o meno lunghi, quindi, a questo scopo, verrà aperto l’editor predefinito di sistema (variabile di sistema EDITOR per gli ambienti UNIX ); questa ma anche questa scelta si può personalizzare nel seguente modo:
git config --global core.editor [comando che avvia l'editor] -
Merge tool: quando si lavora sugli stessi file è inevitabile che qualche modifica possa “entrare in conflitto”, perciò, in questi casi, si possono utilizzare deglli strumenti di “fusione” (merge), che servono ad attuare un’unione “controllata” delle modifiche in conflitto; spesso si richiede che questo intervento venga eseguito manualmente da parte di
git, quindi è bene tenersi uno strumento preferito (consiglio meld), specificandolo con il comando:git config --global merge.tool [comando che avvia lo strumento di merge]
Aggiunta e rollback di modifiche all’area di staging
Dopo aver apportato delle modifiche al progetto, la prima fase che bisogna considerare è quella di aggiungere le nostre modifiche alla staging area. Quest’operazione si fa semplicemente così:
git add [percorsofile]
Si possono anche indicare più percorsi e quindi più file, così come una cartella intera, per selezionare tutti i file che sono stati modficati al suo interno. Per evitare di selezionare tutti i file, o tutte le cartelle, singolarmente, si può scrivere un generico:
git add .
direttamente nella cartella padre del progetto ed aggiungere, in un colpo solo, tutti i file modificati.
Situazione inversa: dalla staging area alla working area
Si può invertire il processo di add con il comando remove sulla cache:
git rm --cached [nomefile]
Nel caso di rimozione di tutti i file o di un’intera cartella, dovete indicare il parametro di **ricorsione -r** in questo modo:
git rm --cached -r [percorso cartella o .]
Questo comando può correggere la retroattività del gitignore già enunciata.
Se nel processo sono eliminati erroneamente dei file, bisogna seguire un altro procedimento. In quel caso, potrebbe essere necessario intervenire, invece, con questi due comandi:
git reset
git checkout --
La prima istruzione annullerà, quindi, l’operazione di add, senza recuperare, però, effettivamente i file, procedimento che verrà effettuato, invece, tramite la seconda.
Eliminare una modifica specifica
L’operazione di checkout, in verità ,è un po’ più complessa e ha diverse funzioni, tra cui quella di poter eliminare le modifiche su specifici file:
git checkout -- nomefile
Così facendo, il file nomefile viene ripristinato a come era prima delle modifiche.
Dallo staging al commit
La prossima fase è quella di registrare i cambiamenti sul repository locale. Questa operazione, come già detto in precedenza, è denominata commit.
La commit deve essere accompagnata da un breve messaggio che spiega il contenuto delle modifiche. Questi messaggi potranno poi essere letti in un momento successivo, perciò è importante che abbiano un senso e che aiutino a capire come si è evoluta la storia di un progetto.
Durante questa fase è importante aver configurato il nome e l’email dell’utente (sezione Configurazione utente).
Per creare un commit la struttura del comando deve essere simile alla seguente:
git commit -m "messaggio di commit" <nomi file>
È ovviamente possibile indicare anche più file, oppure un nome di cartella,(. nella cartella padre per indicarle tutte) per effettuare, in questo caso, il commit di tutti i file che sono stati modificati al suo interno, includendo anche le sue sottocartelle. Se il percorso non viene specificato, git interpreterà tutto questo come un “tutti gli aggiornamenti”. Alcune volte (come nel caso della rimozione di un file in cache) è necessario non specificare nessun percorso.
In verità, per fare un commit complessivo di tutti i file potrebbe essere necessario utilizzare il comando:
git commit -a
che genera, inoltre, un messaggio di commit consigliato (ma commentato), aprendo il proprio editor di sistema per consentirne la modifica.
A necessità, si può modificare l'ultimo messaggio tramite il parametro amend:
git commit --amend
Nota: Buone norme
Per buona norma è meglio eseguire tanti piccoli commit significativi, in modo che ognuno di questi si riferisca ad uno specifico cambiamento del comportamento generale del progetto, piuttosto che effettuare un unico commit, più corposo e più complesso, che descrive una serie di novità.
Questo perché è importante capire quale sia la modifica che, eventualmente, può avere causato, ad esempio, un problema di regressione e poter, quindi, più facilmente, individuare e correggere le righe che riguardano l’anomalia.
Trivia: messaggio di commit casuale
Si può generare un messaggio di commit casuale grazie al sito whatthecommit.com così:
git commit -m "$(curl -s http://whatthecommit.com/index.txt)"
Log dei commit
Una volta effettuato un commit, quest’ultimo viene aggiunto ad una sequenza temporale detta log. La consultazione di questi file permette di verificare la storia delle modifiche, i messaggi, gli autori, le date ed i codici (poichè viene assegnato un codice ad ogni commit).
Queste informazioni sono verificabili con:
git log
Se l’interesse è quello di visionare soltanto il messaggio o il codice dell’operazione si può specificare il parametro --oneline, che riassume queste informazioni:
git log --oneline
Per avere un log ancora più accurato è possibile utilizzare whatchanged:
git whatchanged
che mostra anche un elenco dei file che sono stati cambiati nella storia del commit.
Inverso: dal commit alla working directory con revert
Per invertire un commit ci sono diverse strade: quella più ‘sicura’ è sicuramente il revert, che considera questa azione di regressione come se si trattasse di un commit a sé stante. Questo significa che si ha la possibilità di fare il revert del revert per ritornare alla situazione originale.
L’operazione di revert richiede due fasi:
- la prima è di controllare il codice del commit successivo al quale si vuole tornare tramite l’operazione di log:
git log --oneline
- la seconda consiste nell’effettuare l’operazione vera e propria:
git revert [codice commit]
Ad esempio, supponendo di aver eseguito, di recente, i tre commit seguenti:
- commit aaaa123 - aggiunto file 1
- commit bbbb321 - aggiunto file 2
- commit c1aab12 - modificato file 1
Digitando:
git revert bbbb321
si ritornerà alla situazione in cui ancora non è stato aggiunto il file 2, ma in cui è ancora valido il commit aaaa123.
Se si aggiunge il parametro -n è possibile evitare il commit:
git revert -n codicecommit
Inverso: dal commit alla working directory con reset
Una soluzione più drastica, invece, consiste nell’utilizzare il reset che, a differenza di revert, elimina totalmente la storia fino al commit indicato (necessita sempre di conoscere il codice del commit):
git reset [codice commit]
Se, nel processo, ssi sono eliminati erroneamente dei file, per ripristinare tutto è necessario fare come nel caso dell’add:
git checkout -- .
Inverso: dal commit alla add
In questo caso bisogna fare una distinzione:
- nel caso in cui si sia appena fatto il primo commit, non è possibile tornare alla fase precedente a questo perchè non esiste una storia a cui tornare. Si può però simulare questo evento semplicemente cancellando la storia di git
git update-ref -d HEAD
- Nel caso in cui si è dal secondo commit in poi la soluzione è:
git reset --soft HEAD
?**ATTENZIONE:**
Non utilizzare mai la prima soluzione nel caso della seconda. Otterrete risultati catastrofici!
Riassunto
Un piccolo riassunto di quanto detto:
Stato e comunicazione
Comunicare con il remoto: pull e push
Le operazioni per comunicare con la repository sono:
- pull: per scaricare il codice
git pull [nomerepository1] [nomebranch] - push: per inviare il codice
git push [nomerepository] [nomebranch]
Il nome del branch (spiegato in questa sezione) non è obbligatorio e nemmeno il nome della repository, se ve ne è solo una.
Se si hanno più repository è consigliato anche inserire un “upstream” principale:
git push --set-upstream [nomerepository] [nomebranch]
Così facendo, branch e repository sono sempre selezionati in maniera predefinita se non specificati.
Nota:
Non è possibile fare il push su repository non minimali. Prendiamo come esempio quello delle tre cartelle: avendo cartellaproj, reporemoto1 e repo2, cartellaproj potrà fare push su reporemoto1, ma non su repo2.
Nota:
È consigliato, se si progetta in gruppo, effettuare l’operazione di pull prima di ogni modifica, comunque obbligatoria prima di ogni push.
Controllo aggiornamenti, modifiche e stato
È sempre importante controllare lo stato delle modifiche e la differenza tra vari codici con il repository.
L’operazione di check più semplice da fare è sicuramente:
git status
che mostra le informazioni basilari sui vari cambiamenti.
Per avere informazioni complete anche per quanto riguarda i repository, è meglio dare, prima di controllare lo stato, una fetch sulla repository:
git fetch [nomerepository]
Lo status prende diverse parametri che possono essere più o meno utili, eccone alcuni:
-b nomebranch: visualizza informazioni su quel branch--short: visualizza giusto i file con il tipo di modifica (+ per aggiunto, m per modificato …)--ignored: visualizza i file ignorati
diff
Informazioni più dettagliate, che riguardano le righe modificate nei vari file, potrebbe darlo il comando diff:
git diff nomerepository/nomebranch
Si può usare anche per isolare nello specifico un file o una cartella:
git diff nomerepository/nomebranch -- nomefile
Lo stesso comando può essere utilizzato anche se si vuole vedere lo stato delle modifiche nel proprio workspace senza consultare la repository remota:
git diff nomefile
Nell’esempio cui sopra, se il file “nomefile” è stato modificato aggiungendo una riga, ad esempio apparirà un output con questo stile:
diff --git a/nomefile b/nomefile
index e69de29..d72af31 100644
--- a/nomefile
+++ b/nomefile
@@ -0,0 +1 @@
+asd
Dove accanto i più son visualizzate le aggiunte.
Un uso più consapevole
git è uno strumento molto potente, nato soprattutto per la condivisione di codice in team. Un uso solitario dello strumento è sì, una buona pratica, ma non ne rivela le vere potenzialità del software.
I branch
Il primo passo verso la strutturazione di un buon progetto è delinearne i branch. Per dirla in breve, se si guarda un progetto come una linea ferroviaria che porta un enorme carico da un punto A ad un punto B con un treno, i branch permettono di dividere quel carico su più linee che si diramano dal punto A o successivamente, ma che infine arrivano sempre al punto B.
I vantaggi potrebbero essere quelli di evitare che un incidente rischi di rovinare tutto il carico ma che ne tocchi solo una parte, o ancora che alcuni percorsi permettano di trattare un determinato tipo di carico meglio di altri, o quello di utilizzare più treni, così da non affaticarne solo uno, dividendo i tempi e molto altro.
Nel caso in cui la similitudine non vi fosse completamente chiara, seguirà un maggiore chiarimento di a cosa può servire dividere a branch ?
Le diramazioni di git condividono, fino al punto in cui si son divise, gli stessi file nello stesso stato, mentre da quel momento in poi vivono due vite separate fino a che la diramazione non si ricongiunge con il ramo principale. Alcuni esempi di divisioni utili in branch potrebbero essere:
- sviluppare una nuova feature che prima di essere integrata deve essere considerata stabile
- correggere una specifica famiglia di bug, derivati tutti da una parte in particolare di codice malfunzionante ma di cui comunque si conosce bene il comportamento
- lavorare con due tecniche diverse sullo stesso pezzo di codice (due branch), e quindi decidere alla fine quale tenere e quale buttare
- separare sviluppo frontend da quello backend
- altro…
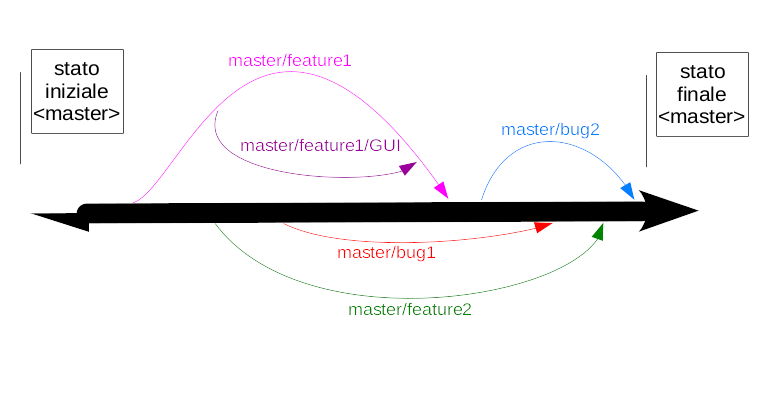
Per creare un branch basta digitare:
git branch [nome branch] [branch originale]
Poi per passare a quel branch:
git checkout [nome branch]
È anche possibile passare ad un nuovo branch e crearlo in un colpo solo:
git checkout -b [nome branch] [branch originale]
Se il branch da cui partire non viene specificato viene inteso quello corrente.
È importante notare che un branch creato a partire da un altro ha tutte le modifiche dell’originale, ma solo **fino al momento della divisione**. Da quel momento in poi qualunque modifica sarà indipendente e non intaccherà né da un lato né da un altro.
A questo punto è giusto porsi il problema: se il branch originale è cambiato, come prelevarsi i cambiamenti in modo da poter continuare a sviluppare sul branch in un’ottica aggiornata? È qui che interviene il concetto di rebase:
git rebase [nome branch aggiornato] [nome branch da aggiornare]
In realtà, il rebase è uno strumento atto in toto a sincronizzare le modifiche di un branch su un altro. È però da evitare se si lavora in team sui due branch da sincronizzare. In tal caso, lo strumento adatto a sincronizzare i due branch potrebbe essere il merge. Per un merge, è necessario posizionarsi sul branch da aggiornare e specificare il sub-branch:
git checkout [nome branch da aggiornare]
git merge [nome branch aggiornato]
Il merge, a differenza del rebase, si occupa di eventuali conflitti.
Per chiudere un branch, o meglio eliminarlo, si proceda con:
git branch -d [nome branch]
Per fare una lista completa dei branch invece:
git branch -a
Tuttavia questo comando non mostra quali sono le relazioni tra vari branch, quindi si può pensare, per informazioni più complete, di digitare:
git log --graph --color --decorate --oneline --all
che fa una lista dei commit dividendo i vari branch se questi non sono sincronizzati.
Qualche esempio
Si parta da una situazione simile all’immagine di cui sopra, e si realizzi qualche cambiamento per capire la struttura dei branch:
# creando il branch feature1
git branch feature1
git checkout feature1
# simulandone una modifica
touch feature1.txt
git add .
git checkout -m "aggiunta la prima feature"
# creando il branch gui e partendo da feature
git checkout -b gui feature1
# si simuli un'aggiunta
touch feature1.gui
git add .
git commit -m "FEATURE1/GUI: $(curl -s http://whatthecommit.com/index.txt)" # commit con testo casuale
# passaggio al branch feature1
git checkout feature1
# simulando una modifica
echo "una nuova riga nella feature" > feature1.txt
# rebase di gui, ci si ritroverà la modifica di feature
git rebase feature1 gui
git checkout gui
# ulteriore modifica
echo "aggiunta la gui a feature" >> feature1.txt
# merge
git checkout feature1
git merge gui
# si può eliminare il branch gui
git branch -d gui
# chiudere il branch feature allo stesso modo
git checkout master
git merge feature1
git branch -d feature1
Si può pensare di realizzare anche il resto della struttura.
Le GUI
In un articolo di questo genere non possono sicuramente mancare le GUI: per quanto sia bello e nerd utilizzare il terminale (e consiglio fortemente di fare un periodo di training SOLO con il terminale) a fini di produttività è indispensabile l’utilizzo di qualche git-client che abbia dell’interfaccia grafica.
In alcune distribuzioni, Git viene installato già con un suo client chiamato gitk richiamabile così da terminale:
gitk
Il software richiamato in questo modo traccia solo le modifiche del branch corrente, e per una prospettiva completa consiglio di dare:
gitk --all
Altri client che consiglio, poichè multiplatform, sono:
- smartgit
- giteye
- gitg
- git cola
- ecc…
Ma a tal proposito, git provvede già una pagina con tutte le GUI migliori, raccolte anche per sistema operativo (compresi Android e iOS).
Per maggiori informazioni, dubbi e chiarimenti, non esitate a fare domande sul nostro gruppo Telegram.