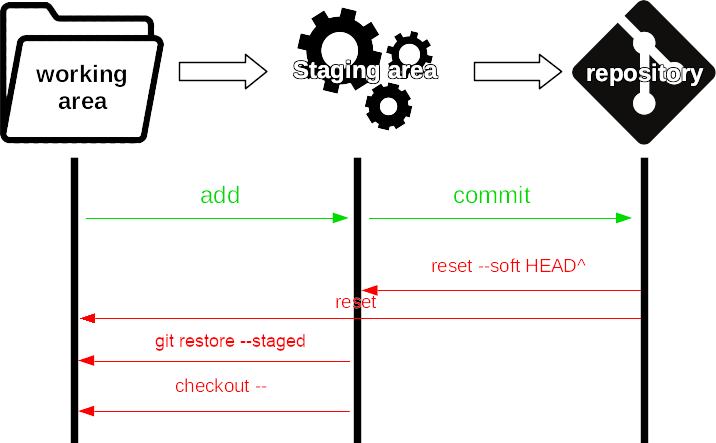
→ Articolo successivo, parte 5: remote e branch
Quando si parla di software di versioning, Git è sicuramente il primo programma che ci viene in mente. Rappresenta l’alternativa più diffusa a sistemi come svn, utilizzata anche in ambito enterprise.
Rappresenta anche uno dei primi scogli che dipendenti alle prime armi affrontano in azienda.
Ecco quindi una guida passo passo a Git, parte 4: approfondimento branch.
Obiettivi
Questo articolo affronterà i seguenti argomenti:
- scopo dei branch
- rebase di branch
- merge di branch
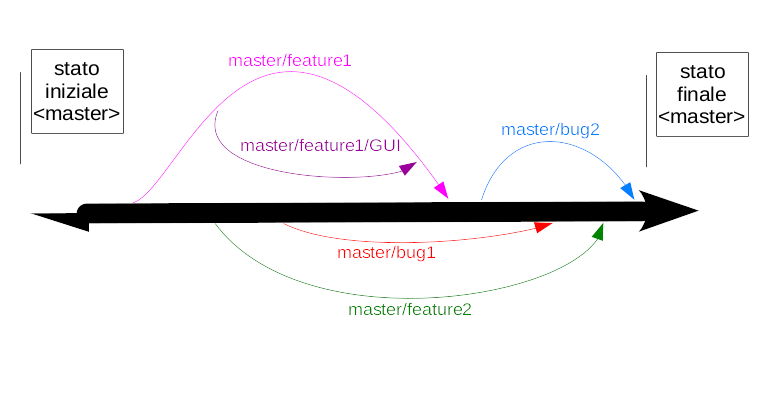
Branch Strategy
Come già spiegato in precedenza, GIT permette di creare rami paralleli in cui poter gestire contemporaneamente varie versioni del progetto.
Il primo passo verso la strutturazione di un buon progetto è delinearne i branch.
È importante notare che un branch creato a partire da un altro ha tutte le modifiche dell’originale, ma solo fino al momento della divisione. Da quel momento in poi qualunque modifica sarà indipendente e non intaccherà né da un lato né da un altro.
Le diramazioni di git condividono, fino al punto in cui si son divise, gli stessi file nello stesso stato, mentre da quel momento in poi vivono due vite separate fino a che la diramazione non si ricongiunge con il ramo principale. Alcuni esempi di divisioni utili in branch potrebbero essere:
- sviluppare una nuova feature che prima di essere integrata deve essere considerata stabile
- correggere una specifica famiglia di bug, derivati tutti da una parte in particolare di codice malfunzionante ma di cui comunque si conosce bene il comportamento
- lavorare con due tecniche diverse sullo stesso pezzo di codice (due branch), e quindi decidere alla fine quale tenere e quale buttare
- separare sviluppo frontend da quello backend
- altro…
La gestione di “divisione” dei branch è un concetto che va deciso con il team e rientra in quella pratica definita come “branch strategy”. Con questo termine si intendono tutte quelle scelte di team quali:
- Nomi dei branch
- La gestione di riconciliazione dei branch
- La politica di push/pull
- Gestione dei branch di backup e supporto
- etc…
Nomi dei branch
Esistono delle convenzioni comuni per i nomi dei branch, in genere:
masteromainè generalmente chiamato branch di produzione. Ovvero è quel branch dove vi è una versione stabile del software.- In genere si crea un branch di
developche viene utilizzato come branch di sviluppo. Ovvero quel branch dove vengono portati avanti gli sviluppi fino a che non si concludono e possono essere portati su master. - Per gestire le nuove funzionalità generalmente vengono creati dei branch i quali nomi iniziano con
feature/. - Per gestire aggiornamenti vecchi del software bloccati su versioni stabili, si usano branch i quali nomi iniziano con
support/ - Per gestire invece i bug sui branch di supporto, si usano i branch di hotfix che iniziano con
hotfix/ - Per gestire le transizioni di nuovi rilasci normalmente si utilizzano dei branch il quale nome inizia con
release/, su questo si fanno poi le varie merge per costruire il rilascio e quindi poi si passa tutto in develop.
Versioni del progetto in relazione al branch
I path dei branches che iniziano con hotfix/, support/ e release/ normalmente terminano con il numero di versione del progetto, la domanda potrebbe essere: come si costruisce il numero di una versione?
Normalmente il numero di versione di un progetto è diviso in tre campi, separati da un punto MAJOR.MINOR.HOTFIX, è presto detto il significato di questi tre termini:
- MAJOR, è il primo campo, e rappresenta tutte le versioni dette “break changing”, ovvero tra una MAJOR ed un altra ci si aspetta non ci sia retrocompatibilità perché cambiano dei punti cardine del progetto.
- MINOR, è il secondo campo e rappresenta tutte le versioni che son compatibili tra di loro all’interno della stessa MAJOR ma in cui ci son cambiamenti migliorativi (spesso nuove features o correzioni di bug minori)
- HOTFIX, è il terzo campo e rappresenta la correzione di bug di una coppia
MAJOR.MINORche è stata indicata come “versione di supporto”, ovvero non vi son più sviluppi attivi di sopra.- Per fare un esempio più pratico della differenza tra MINOR e HOTFIX in caso di bug, si può immaginare che una certa versione di un software stabile sia adesso stata superata di una MAJOR. Su quel branch di supporto non è attivo alcun sviluppo (perché è in preparazione una nuova versione) ma si scopre un certo bug, grave, che deve essere corretto. Si può quindi creare una versione di HOTFIX per correggerlo.
Rinominare un branch
Per rinominare un branch, posizionarsi sul branch tramite checkout:
git checkout NOMEVECCHIOBRANCH
In seguito si può scrivere:
git branch -m NUOVONOMEBRANCH
Rebase
Si supponga il seguente scenario:
- Si è staccato un branch
xper fare una modifica dadevelop. - Nel mentre che si lavora sul branch
x,developviene portato avanti.
A questo punto è giusto porsi il problema: se il branch originale è cambiato, come prelevarsi i cambiamenti in modo da poter continuare a sviluppare sul branch in un’ottica aggiornata? È qui che interviene il concetto di rebase:
git rebase NOMEBRANCH
Ad operazione finita, il branch corrente si sarà spostato sul branch di rebase, assorbendo tutti i commit.
Situazioni di conflitto del rebase
Potrebbe succedere che l’operazione di rebase si interrompa a causa di un conflitto. Il concetto di conflitto è molto semplice: se vi sono due modifiche sullo stesso file git tenta di fare una “fusione” dei due file in maniera intelligente, tuttavia se le modifiche son avvenute nella stessa parte del codice invece di procedere, git interrompe l’operazione e delega all’utente le scelte da fare su come unire i due files.
In caso di conflitto durante un merge esce il messaggio di errore:
CONFLITTO (contenuto): conflitto di merge in percorso/file
Se capita un conflitto, il primo step da seguire è quello di aprire i file che hanno creato conflitto e risolverli. In genere le zone determinate da questa situazione son delineate dai caratteri <, = e >, come in questo caso:
Prima riga
seconda riga
terza riga
<<<<<<< HEAD
quarta riga con altra modifica
=======
quarta riga con modifica da repo1
>>>>>>> b186b01f45a3b8ba301936fe1f705083f9b40cfd
quinta riga
sesta riga
La quarta riga nell’esempio di cui sopra è andata in conflitto, la prima zona (contrassegnata da < e quindi HEAD) è quella locale; mentre la seconda zona preceduta dai segni = è quella in ingresso (dal branch di rebase).
Per gestire il conflitto bisogna decidere quale delle due parti tenere e, eventualmente, effettuare ulteriori modifiche. Eliminare quindi i caratteri in eccesso (<, = e >).
Una volta gestito il conflitto, si aggiunge allo stage e si committa:
git add percorso/file/conflitto
git commit
Quindi si può continuare con la rebase:
git rebase --continue
Se invece si vuole interrompere definitivamente il processo si può scrivere:
git rebase --abort
Merge
Una volta che si stacca un branch e si modifica, è una pratica molto comune quella di “riunirlo” in un secondo momento.
Questa pratica è detta “merge” e si effettua come segue:
git checkout NOMEBRANCHORIGINALE
git merge NOMEBRANCHDAUNIRE
Scegliere l’algoritmo di fast-forward
Se ci son state modifiche sugli stessi file è possibile gestire quale genere di algoritmo utilizzare per fare la fusione, per far si che git si occupi di tutto (a meno di conflitti) scegliere quello di fast-forward:
git merge NOMEBRANCHDAUNIRE --ff
Gestione conflitti
Anche la merge può entrare in conflitto ovviamente. In tal caso risolvere i conflitti come visto per il rebase, fare una git add ed una commit, quindi il conflitto viene automaticamente risolto.
La pull come merge
La pull viene vista come una merge tra il repository locale e quello remoto, può quindi entrare in conflitto e si può specificare, in caso di modifiche concorrenti, il flag di fast forward:
git pull NOMEREMOTE NOMEBRANCH --ff
Eliminare un branch
Per chiudere un branch, o meglio eliminarlo, si proceda con:
git branch -d [nome branch]
Lista dei branch remoti
Per fare una lista completa dei branch invece:
git branch -a
Tuttavia questo comando non mostra quali sono le relazioni tra vari branch, quindi si può pensare, per informazioni più complete, di digitare:
git log --graph --color --decorate --oneline --all
che fa una lista dei commit dividendo i vari branch se questi non sono sincronizzati.
]]>